
GCD使用详解 下篇
Dispatch Queue的一些函数
GCD还提供了许多很有用的API用于控制队列中的任务。接下来,我们挨个看看这些API,你就明白为什么GCD如此强大。
dispatch_set_target_queue
dispatch_set_target_queue函数用于设置一个”目标”队列。这个函数主要用来为新创建的队列设置优先级。当用dispatch_queue_create函数创建一个队列后,无论创建的是并行队列还是串行队列,队列的优先级都和全局队列的默认优先级一样。创建队列后,你可以用这个函数来修改队列的优先级。下面的代码演示了如何给一个串行队列设置background优先级。
|
上面代码中,dispatch_set_target_queue函数的第一个参数是被设置优先级的队列,第二个参数是一个全局队列,它会被作为目标队列。这段代码会使队列拥有和目标队列相同的优先级(稍后会解释这里的机制)。如果你将主线程队列或者全局队列传递给dispatch_set_target_queue函数的第一参数,结果不确定,最好不要这么干。使用dispatch_set_target_queue函数不仅能够设置优先级,也能创建队列的层次体系。如图7-8所示,一个串行队列被设置成了多个串行队列的目标队列,在目标队列上,一次只会有一个队列被执行。
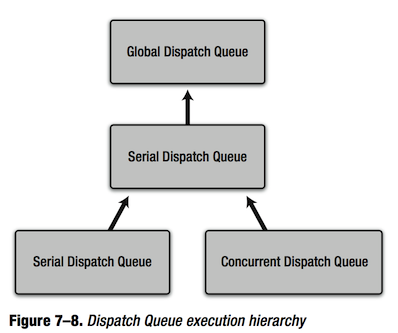
这样,当有些任务你不想它们同时运行而又不得不将它们添加到不同的串行队列中时,就可以避免它们同时运行。(虽然,实际上我也不知道什么情况下会有这样的需求。)
dispatch_after
dispatch_after用于在队列中定时执行任务。当你想在一段时间后执行一个任务,那么就可以用这个函数。例如,下面代码中,3秒过后,指定的block会被添加到主线程队列上。
|
代码中,“ull”代表unsigned long long类型。请注意,dispatch_after函数并不会在指定的时间立即执行任务,时间到后,它只将任务添加到队列上。所以,这段代码的作用和你在3秒钟后用dispatch_async函数将block加到主线程队列上是一样的。主线程队列是在RunLoop上执行的,因此,假如RunLoop每1/60秒执行一次任务,那么上面添加的block会在3秒~3+1/60秒后被执行。如果主线程队列上添加了很多任务,或者主线程延迟了,时间可能更晚。所以,将dispatch_after作为一个精确的定时器使用是有问题的。如果你只是想粗略的延迟一下任务,这个函数倒是挺适用的。
函数的第二个参数指定了一个dispatch队列,用于添加任务。第三个参数,是一个block,即要执行的任务。第一参数指定了延迟的时间,是一个dispatch_time_t类型的参数,可以用dispatch_time函数或dispatch_walltime函数来创建。
dispatch_time的第一个参数是指定的起始时间,第二个参数是以纳秒为单位的一个时间间隔。这个函数以起始时间和时间间隔来创建一个新的时间。如示例所示,通常以DISPATCH_TIME_NOW来作为第一个参数的值,它表示当前的时间。在下面这段代码中,你可以得到一个dispatch_time_t类型的表示1秒钟之后的时间的变量。
|
第二个参数中,NSEC_PER_SEC和数字的乘积会得到一个以纳秒为单位的时间间隔值。如果使用NSEC_PER_MSEC,就会得到一个以毫秒为单位的时间间隔值。下面的代码,演示了如何获得一个150毫秒之后的时间。
|
dispatch_walltime函数以一个timespec结构体类型(来自POSIX接口)的时间来创建一个dispatch_time_t类型的时间。dispatch_time主要用于创建一个相对时间。dispatch_walltime函数则是用于创建一个绝对时间。比如,你可以用dispatch_walltime函数为dispatch_after函数创建一个诸如“2011年11月11日 11:11:11”这样的绝对时间,用来做一个闹钟,但是它是低精度的。通过NSDate类对象,可以很方便的创建一个timespec结构的时间,如下面代码所示。
|
Dispatch Group
Dispatch Group 用于创建一组队列。有时你可能需要等待队列中的所有任务完成后才执行另一个任务。当所有任务都在一个串行队列里面的时候,你只需要将最后一个任务加到队列的末尾就可以了。但如果你在使用并行队列的时候或者面对多个队列的时候,就没那么简单了。这种情况下,就可以使用 Dispatch Group 。下面的代码演示了 Dispatch Group 的基本用法,代码中,3个block被添加到了全局队列上,当所有block都完成后,最后一个block会在主线程队列上执行。
|
代码的执行结果可能会是这样:
|
任务的执行顺序不会每次都相同,因为它们是被添加到全局的并发队列上的,会并发的在多个线程上执行。但“done”总是会在最后被执行。
不管是在何种队列上,dispatch group 都会监控任务的完成情况。当它发现所有任务都完成后,最后一个任务就会被加到队列上。这就是dispatch group的使用方法。
首先,用dispatch_group_create函数创建一个dispatch_group_t类型的dispatch group。因为函数名字中包含create,当你不再需要这个dispatch group后,要将它释放掉。与dispatch队列一样,用dispatch_release函数释放它。
接着,像用dispatch_async函数那样,用dispatch_group_async函数将block加到指定的队列上。与dispatch_async函数的不同之处在于,这个函数需要一个dispatch group来作为第一个参数。当调用dispatch_group_async函数的时候,block就和group关联起来了。和将block添加到dispatch队列的情况类似,当一个block和dispatch group关联起来后,block也就会通过dispatch_retain函数获得dispatch group的所有权。当block执行完毕后,也会通过dispatch_release函数释放掉对group的所有权。你不需要去关心block和group是如何关联起来的。
最后,dispatch_group_notify函数将一个block加到了一个dispatch队列上。这个block会在group中的所有任务完成后被执行。函数的第一个参数是一个要通知的dispatch group。当和这个group关联的所有任务完成后,第三个参数中的block会被添加到指定的队列(第二个参数)上。不管传递给dispatch_group_notify函数的是何种队列,当block被添加到队列上时,group相关联的所有任务必定已经全部完成了。
另外,如下代码所示,你还可以使用dispatch_group_wait函数,等待dispatch group的所有任务完成。
|
dispatch_group_wait函数的第二个参数是等待的时间,dispatch_time_t类型。这个例子中,DISPATCH_TIME_FOREVER表示永远等待。它会一直等待,直到dispatch group相关联的所有任务都完成。不能在中途取消等待。
和dispatch_after函数中类似,你也可以设置等待1秒种。如下代码所示。
|
dispatch_group_wait函数没有返回0,则说明当指定的等待时间过后,dispatch group相关联的一些任务仍然还在执行。如果它返回0,则说明所有任务都已经完成。如果指定的等待时间是DISPATCH_TIME_FOREVER,那么dispatch_group_wait函数肯定会返回0,因为必须要等待所有任务完成后才能返回。
这里的“wait”是指当dispatch_group_wait函数被调用后,函数不会立即返回,当前执行dispatch_group_wait函数的这个线程会停止,当超过指定的等待时间后或者dispatch group相关联的所有任务都完成后,这个线程才会继续,函数才会返回结果。
当等待时间被指定为DISPATCH_TIME_NOW的时候,这个函数可以被用来检查dispatch group相关联的所有任务是否都已经完成。
|
例如,你可以在主线程的RunLoop上毫无延迟的检查每次loop中是否所有任务都完成了,然后再做某些操作。尽管可以这样干,但是我建议还是用dispatch_group_notify函数好些,这样你的代码可以更简洁。
dispatch_barrier_async
dispatch_barrier_async函数用于等待队列中其他任务完成。前面我们提到过,当你访问数据库或者一个文件的时候,你可以用串行队列来避免数据冲突。但实际上,当有其他更新数据或读取数据的操作在进行的时候,不应该同时再进行更新数据的操作。但是多个读取操作是可以同时进行的,这样可以更高效的访问数据。这种情况下,更新数据的操作必须放到一个串行队列中,并且只有当串行队列中没有任何更新操作在执行的时候,这些读取操作才能被放到一个并行队列中。你要确保不能在更新操作完成前开始读取操作。你可以用dispatch group和dispatch_set_target_queue函数来实现这种功能,但是会很复杂。GCD提供了一个更好的解决方案,就是dispatch_barrier_async函数。下面的代码创建了一个并发队列,然后向队列中添加了一些读取操作。
|
接下来,想象一下,在blk3_for_reading和blk4_for_reading之间要进行一个写数据的任务,任务完成后,blk4_for_reading才开始读取更新过后的数据。
|
如果我们像下面代码一样,只是简单的用dispatch_async函数来添加写数据的操作,写操作之前添加的读取操作同样有可能会意外地读取到更新过后的数据。程序还可能因此而崩溃,此外,还会引起数据冲突和其他许多问题。
|
这种情况下就该用dispatch_barrier_async函数了。使用dispatch_barrier_async函数,你可以将一个任务在所有任务都完成后才加入到并发队列中。当用dispatch_barrier_async添加的任务完成后,并发队列中的任务又恢复并发执行。图7-9演示了下面这段代码的执行情况。
|
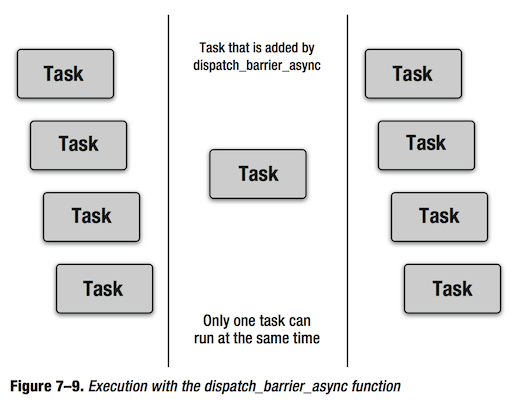
就是这么简单,只需要用dispatch_barrier_async代替dispatch_async。
所以,为了更高效的访问数据库或文件,尽情的使用并发队列和dispatch_barrier_async函数吧。
接下来,我们来看看dispatch_sync函数,看起来和dispatch_async函数很像,对吧?
dispatch_sync
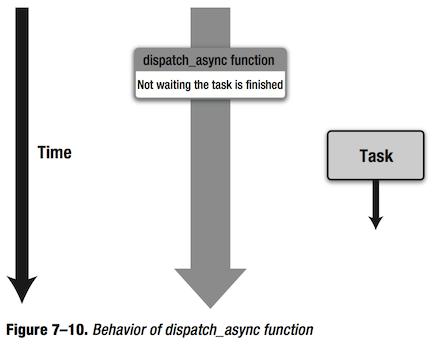
dispatch_sync函数和dispatch_async函数类似都是用于将一个任务添加到一个队列上,但是dispatch_sync会等待添加到队列上的任务执行完毕。而dispatch_async函数名字中的“async”代表异步(asynchronous)。因此,它将一个block添加到一个队列上后,block会异步的执行,dispatch_async不会等待任务执行完毕。如图7-10所示。
与此对应的同步版本(synchronous)——dispatch_sync函数,它将block添加到队列上后,会等到block执行完毕后才返回。如图7-11所示。
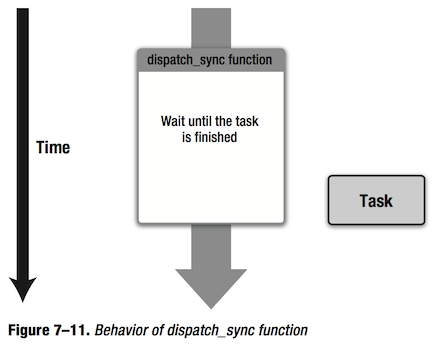
与前面介绍过的dispatch_group_wait函数类似,等待表示当前线程会暂停。例如,你可能想在主线程上使用一个在全局队列上运行的任务的结果,这种情况,你就可以用dispatch_sync函数。
|
当dispatch_sync函数被调用后,函数不会立即返回,它会等待任务执行完成后才返回。这有点像是一个简单版的dispatch_group_wait函数。dispatch_sync的使用也非常简单,但它可能会引起死锁问题。例如,下面的代码如果在主线程上运行,就会造成死锁。
|
block被添加到了主线程队列上,但同时主线程又会等待block完成后才能继续,所以最后这个block永远也无法被执行。
再看下面这段代码:
|
dispatch_async添加block后,虽然会立即返回,但是因为dispatch_async添加的这个block是加到主线程队列上的,而后面dispatch_sync这个函数添加的block也是加到主线程队列上的,也会造成死锁。
同样,这个问题也会发生在一个串行队列上。
|
另外,类似的dispatch_barrier_async函数中包含了一个“async”,同样这个函数也有一个“sync”版本,叫做dispatch_barrier_sync。当队列中的所有任务执行完成后,由dispatch_barrier_sync函数添加的这个任务会开始执行,并且函数会等待任务完成后才返回,像dispatch_sync函数一样。
当使用这些同步的(synchronous)API的时候,比如dispatch_sync,它们会等待任务完成后才继续。所以,当你使用这些API的时候要想想为什么,注意不要造成死锁。
dispatch_apply
dispatch_apply函数与dispatch_sync函数和dispatch group有点关系。它用来将一个block多次添加到dispatch队列上,然后等待所有任务完成。
|
代码执行结果如下:
|
因为是执行在全局队列上面的,所以每个任务的执行时间不一定相同。但是,“done”总会在最后执行,因为dispatch_apply函数会等待所有任务完成。
函数中,第一个参数是添加次数,第二个参数是目标队列,第三个参数是要添加到目标队列上的block。在上面这个例子中,可以看到block带有一个参数,这个参数是用来区分是第几次的block,因为block会被多次添加到队列上。比如,如果你想要对一个NSArray中的所有对象进行某些操作的时候,就可以不用for循环的方式了,如下代码所示。
|
如你所见,在一个全局队列上对数组中的所有对象执行相同的处理非常容易。dispatch_apply函数会像dispatch_sync函数一样等待所有任务完成,所以建议你将dispatch_apply和dispatch_async函数一起结合使用。如下所示。
|
好了,休息一会儿。我们稍后再接着看dispatch_suspend和dispatch_resume函数。
dispatch_suspend/dispatch_resume
这两个函数是用来暂停或继续队列运行的。当你想要往一个dispatch队列上添加多个任务,并且不想在全部任务添加完毕前执行任何一个任务,这个时候,你可以先让队列暂停运行,在你处理完后再让队列继续运行。
|
要注意的是,暂停只会禁止执行还未开始执行的任务,已经处于执行中的任务无法暂停。在队列恢复运行后,未开始执行的任务就可以正常执行了。
Dispatch Semaphore
当你需要对一小部分间隔时间较短的任务做并发控制的时候,信号量(Semaphore)会比串行队列或者dispatch_barrier_async更好用。
前面我们有提到,并发读取或更新数据时很容易造成数据冲突或者程序崩溃。你可以用串行队列或者dispatch_barrier_async函数来避免这种问题。但是有时需要在很短的时间间隔里做一些并发控制。比如,下面这个例子。
|
这个例子中,在一个全局并发队列上向数组中加入数据,会有多个线程同时操作数组。由于NSMutableArrary并不支持多线程,因此当多个线程同时操作数组的时候,可能会扰乱数组中的数据。这种情况,我们可以用dispatch semaphore来解决。
Dispatch semaphore是一个带有计数器的信号量。这就是多线程编程中所谓的计数器信号量。信号量有点像一个交通信号标志,标志起来的时候你可以走,标准落下的时候你要停下来。Dispatch semaphore用计数器来模拟这种标志。计数器为0,队列暂停执行新任务并等待信号;当计数器超过0后,队列继续执行新任务,并减少计数器。
要创建一个dispatch semaphore,用dispatch_semaphore_create函数。
|
函数的参数是指计数器的初始计数。同样,因为函数名字中有”create”单词,用这个函数创建的对象,在你不需要它之后,要用dispatch_release释放掉。
|
dispatch_semaphore_wait函数用于等待一个信号量。当信号量的计数器变成1(及以上)数字后,函数停止等待,使计数器减1,并返回。函数的第二个参数是指定的等待时间,dispatch_time_t类型。dispatch_semaphore_wait函数的返回值和dispatch_group_wait函数的返回值类型一样,不同的返回值代表了不同的结果。如下代码所示。
|
dispatch_semaphore_wait函数返回0的时候,可以安全的运行你的任务。任务完成后,要调用dispatch_semaphore_signal函数,使信号量的计数器加1。(译注: 这就有点类似于,-1表示你占用一份资源;用完后,+1表示你用完了,空余了一份资源出来。其他等待的人收到信号后,就可以用你这份空余的资源。)
现在再来看看前面那个例子中使用信号量是什么样的。
|
dispatch_once
dispatch_once函数用于确保一个任务在整个程序运行过程中,只会被执行一次。下面的代码是初始化一个对象时的典型做法。
|
如果用dispatch_once函数来实现就更简洁了。
|
两种方式没有多少差别。前面一种,在大多数情况下是安全的,但在多核CPU上时,“initialized”变量可能在被重新赋值的同时又在被读取,这会导致初始化操作被执行多次。然而如果你用dispatch_once来实现的话,就没有这种担忧了,代码在多线程环境中也是安全的。因此在创建一个单例对象时,dispatch_once函数很有用。
Dispatch I/O
读取一个大文件的时候,你可能会想到,如果将文件分成若干小块再用全局队列并发读取,这样会比正常情况下一次性读取整个文件快很多。对于目前的I/O硬件来说,并发读取可能确实会比单线程读取要快。要想获得更快的读取速度,可以使用Dispatch I/O和Dispatch Data。当你使用Dispatch I/O读写文件的时候,文件会被分成某个固定大小的文件块,你可以在一个全局队列上访问它们。
|
如代码中所示,读取操作会分块进行。用Dispatch Data很容易将读取到的数据组合起来。如下,苹果官方的dispatch I/O和dispatch data例子。
|
这是来自苹果的系统日志API(Libc-763.11 gen/asl.c)的源代码。dispatch_io_create函数创建了一个dispatch I/O。它指定了一个会在发生错误的时候被执行的block,以及执行block的队列。dispatch_io_set_low_water函数指定了每次读取操作最多可以读取的数据长度(数据会按这个尺寸分块)。dispatch_io_read函数在全局队列上开启读取操作。每当一块数据被读取后,数据作为参数会被传递给dispatch_io_read的回调函数,因此,block就可以扫描或组合数据了。
如果你想读取文件的时候速度快些,就试试用dispatch I/O吧。
